Hoe ik een volautomatische failover bouwde tussen twee cloudproviders — en wat dit betekent voor organisaties die serieus zijn over digitale onafhankelijkheid
De aanleiding: een vraag die niet losliet
In een eerder artikel beschreef ik hoe ik een volledig soevereine cloud bouwde op Europese infrastructuur — van geautomatiseerde servers op Scaleway tot een volwaardige kantooromgeving met open source software. Die reis begon bij een fundamentele vraag: wat als een Amerikaanse cloudprovider jouw toegang blokkeert?
Het antwoord dat ik toen gaf was technisch en architecturaal: gebruik Europese providers, open source, en zorg dat je infrastructuur beschreven staat als code zodat je haar volledig begrijpt en beheert. Maar er bleef een vervolgvraag hangen die concreter en urgenter is. Niet: “hoe bouw je een soevereine cloud?” maar: “hoe zorg je dat je blijft werken als je primaire cloud wegvalt?”
Een zakelijke relatie stelde mij precies die vraag. Hij gebruikt een grote Amerikaanse cloudprovider voor kritieke bedrijfsprocessen. De zorg was concreet: wat als die cloud onbereikbaar wordt vanuit Europa? Niet door een technische storing, maar door een politieke beslissing, exportcontrole, of sanctie? Hoe lang duurt het voordat zijn bedrijf weer operationeel is? Wie beslist dat? Heeft hij überhaupt enige controle? Bovendien moeten de kritieke bedrijfsprocessen geborgd blijven — ook vanuit de wet- en regelgeving waarmee hij te maken heeft.
Ik wilde dat ik hem een werkende oplossing kon laten zien — niet een whitepaper, niet een architectuurplaat, maar een live demonstratie. Dat werd dit project.
Een onafhankelijke keuze van providers
Voordat ik beschrijf wat ik heb gebouwd, is een belangrijk uitgangspunt vermeldenswaard: als onafhankelijk IT-professional ben ik niet gelieerd aan welke cloudprovider dan ook. Ik verkoop geen licenties, ontvang geen commissies, kortom ik ben onafhankelijk en neutraal wat dat betreft.
Voor dit project heb ik bewust twee willekeurige providers gekozen die het vraagstuk het beste illustreren: Amazon Web Services als voorbeeld van een grote, niet-Europese cloudprovider — de situatie waarin veel organisaties zich bevinden — en Scaleway als voorbeeld van een Europese provider, Frans bedrijf met datacenters in Amsterdam en Parijs, volledig onder Europese jurisdictie.
Die keuze is niet een aanbeveling. Het gaat om het principe: elke combinatie van een primaire cloud en een Europese failover werkt volgens dezelfde architectuurlogica. De oplossing is bewust provider-agnostisch ontworpen. Morgen kan ik diezelfde aanpak toepassen met Microsoft Azure als primaire cloud en OVHcloud als failover — de onderliggende architectuur verandert niet. De primaire cloud hoeft overigens geen Amerikaanse provider te zijn — ook een volledig Europese multi-cloud opstelling is met dezelfde aanpak realiseerbaar.
Dat is precies wat digitale soevereiniteit vereist: geen afhankelijkheid van één partij, en de technische capaciteit om te wisselen als dat nodig is.
Wat ik heb gebouwd
Zes code-repositories. Vier projecten. Één geïntegreerde multi-cloud architectuur die volledig automatisch overschakelt naar de Europese cloud wanneer de Amerikaanse cloud onbereikbaar wordt — en even automatisch terugschakelt wanneer die herstelt.
De architectuur heeft drie lagen, elk met een heldere en bewuste verantwoordelijkheid.
De soevereine fundering — buiten de kwetsbare zone
Alles wat bepaalt wie toegang heeft en waar internetverkeer naartoe gaat, draait op Europese infrastructuur in Amsterdam — volledig buiten de Amerikaanse juridische invloedssfeer. Twee diensten vormen dit fundament.
De eerste is een open source identiteitsplatform genaamd Keycloak. Gebruikers en medewerkers loggen niet rechtstreeks in bij de Amerikaanse of Europese cloud — ze authenticeren altijd via dit centrale systeem, krijgen een digitaal toegangsbewijs, en dat bewijs wordt door beide clouds erkend. Als de Amerikaanse cloud geblokkeerd wordt, werkt de toegangscontrole gewoon door. Dezelfde gebruiker, dezelfde rechten, andere cloud. Het identiteitsbeheer is onttrokken aan de kwetsbare zone.
De tweede is een open source DNS-server genaamd PowerDNS, met een ingebouwde automatische bewaker. Elke dertig seconden controleert deze bewaker of de Amerikaanse cloud nog reageert. Na drie opeenvolgende mislukkingen — negentig seconden — wijzigt het systeem automatisch het DNS-record dat internetverkeer naar de juiste server stuurt. Binnen twee minuten bereiken gebruikers de Europese server, zonder dat iemand een knop heeft hoeven indrukken.
De keuze om beide diensten buiten de Amerikaanse cloud te plaatsen is geen detail — het is de kern van het ontwerp. De DNS-dienst van Amazon is een Amazon-dienst: als Amazon wegvalt, valt ook je DNS weg. Het identiteitsbeheer van Amazon is een Amazon-dienst: als Amazon wegvalt, verlies je ook je toegang tot de hersteltools. Door deze twee kritieke functies op onafhankelijke, Europese infrastructuur te plaatsen, is de failover niet afhankelijk van de cloud die faalt.
De primaire omgeving — de Amerikaanse cloud
Een applicatieserver met een webpagina en een gezondheidscheck-endpoint waar de automatische bewaker elke dertig seconden op controleert. Een database met continue synchronisatie naar de Europese omgeving. En een identiteitskoppeling zodat medewerkers via het centrale Europese identiteitsplatform tijdelijke toegang kunnen aanvragen tot de Amerikaanse cloud — zonder een apart Amerikaans gebruikersaccount nodig te hebben.
De Europese failover — altijd gereed
Een server in warme standby: altijd aan, altijd klaar, maar verwerkt normaal geen productieverkeer. Een database die continu een actuele kopie ontvangt van de Amerikaanse database. Objectopslag als spiegel van de bestanden in de Amerikaanse cloud. Bij een blokkade is deze omgeving binnen drie minuten volledig operationeel — zonder dat een mens iets hoeft te doen.
Gebouwd met Infrastructure as Code en geautomatiseerde pipelines
Wat dit project onderscheidt van een handmatig opgezette omgeving is de volledige automatisering via Infrastructure as Code en GitOps — twee principes die ik ook in mijn vorige artikel centraal stelde, en die hier opnieuw hun waarde bewijzen.
Infrastructure as Code betekent dat de volledige infrastructuur — servers, netwerken, beveiligingsregels, DNS-records, gebruikersrechten — beschreven staat als leesbare code in Git-repositories. Niets bestaat buiten die beschrijving om. Elk onderdeel is gedocumenteerd, versioned, en reproduceerbaar. Een nieuwe omgeving opzetten is een kwestie van de code uitvoeren, niet van handmatige stappen onthouden.
GitOps voegt daar een laag aan toe: geautomatiseerde pipelines bewaken continu of de werkelijke situatie overeenkomt met de beschreven situatie. Afwijkingen worden automatisch gecorrigeerd. Handmatige wijzigingen worden teruggedraaid. De pipeline is de enige weg — en die weg is volledig gelogd en auditeerbaar.
In de praktijk betekent dit voor dit project: de zes repositories werken samen als een gecoördineerd systeem. Wanneer de infrastructuur van het fundament succesvol wordt uitgerold, triggert de pipeline automatisch de configuratie van Keycloak en de DNS-zones. Wanneer de Amerikaanse omgeving wordt uitgerold, triggert die pipeline automatisch een update van de DNS-records. Wanneer de Europese omgeving wordt uitgerold, triggert die pipeline automatisch het platform om het failover-record bij te zetten.
IP-adressen, configuratiewaarden en verbindingsgegevens stromen automatisch van de ene pipeline naar de andere — geen handmatige overtyping, geen kans op fouten, geen hardcoded waarden in configuratiebestanden.
Eén uitzondering is bewust: de definitieve activering van het failover-DNS-record vereist een handmatige goedkeuring van een operator. Infrastructuurwijzigingen die impact hebben op productieverkeer verdienen menselijke goedkeuring. Automatisering en menselijk oordeel vullen elkaar aan — ze vervangen elkaar niet.
Configuratie als code: Ansible en het beheer van identiteiten
Naast de infrastructuur zelf is er een aparte laag voor de configuratie van wat op die infrastructuur draait. Hiervoor gebruik ik Ansible — een open source automatiseringstool die de gewenste situatie beschrijft en die situatie realiseert, ongeacht de begintoestand.
Een inzicht dat dit project scherper maakte: infrastructuur en configuratie hebben fundamenteel verschillende verantwoordelijkheden, en die scheiding bewust handhaven levert een robuuster en veiliger systeem op.
Gebruikers en toegangsrechten beheer je anders dan servers. Als je een gebruiker per ongeluk verwijdert uit een infrastructuurconfiguratie, wil je niet dat het systeem hem automatisch ook uit het identiteitsplatform verwijdert — inclusief alle toegangshistorie en auditrapporten. Met Ansible werkt dat anders: een gebruiker deactiveren betekent uitschakelen, niet verwijderen. De history blijft intact. Dat is niet alleen technisch slimmer, het is ook wat compliance-vereisten zoals NIS2 verwachten.
Het resultaat is één centraal bestand als enige bron van waarheid voor alle gebruikers: wie heeft toegang, met welke rol, en in welke toestand. Een wijziging doorvoeren is zo simpel als dat bestand aanpassen en de pipeline starten. Geen handmatige acties in beheerinterfaces, geen ongedocumenteerde wijzigingen, geen “wie heeft dit ook alweer ingesteld?”
Het operationele dashboard: failover zichtbaar maken
Een architectuur die je niet kunt demonstreren overtuigt niemand. Daarom bouwde ik een operationeel dashboard — een helder, donker bedieningspaneel in NOC-stijl dat de status van beide clouds in realtime toont.
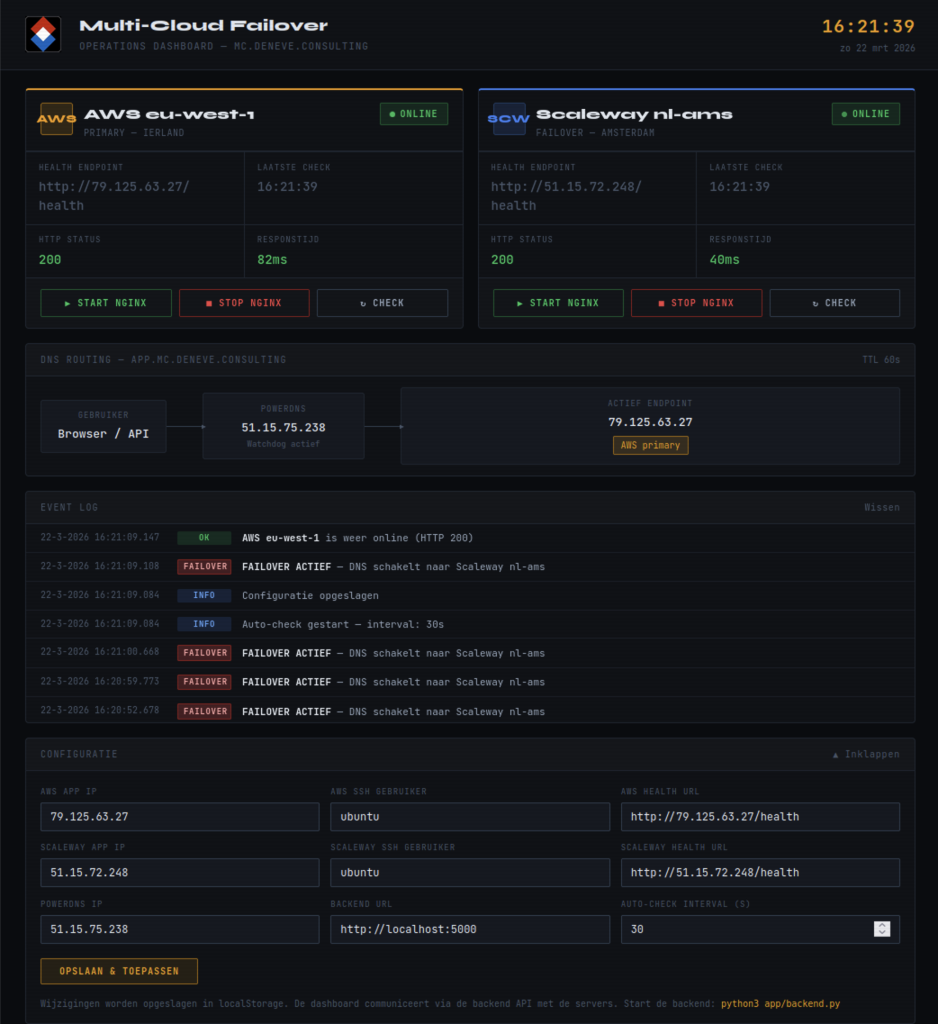
Het dashboard heeft drie functies. Het controleert continu of de applicatieservers op beide clouds bereikbaar zijn en toont de responstijd. Het visualiseert de DNS-routing: welke cloud ontvangt op dit moment het gebruikersverkeer? En het biedt knoppen om de webserver op elke cloud te starten en stoppen, zodat ik de failover live kan demonstreren aan mijn relatie.
Het demoscript is doelgericht eenvoudig. Stop de webserver op de Amerikaanse cloud. Wacht negentig seconden. De DNS-routing schakelt automatisch om. De oranje pagina van de Amerikaanse server maakt plaats voor de groene pagina van de Europese server. Het event log toont elke stap met exacte tijdstempels. Geen scripts die je tijdens de demo moet onthouden, geen handmatige interventies.
Dat visuele bewijs — een live failover binnen drie minuten, volledig automatisch — is wat een whitepaper of architectuurplaat nooit kan bieden.
Wat we hebben bewezen
Na het bouwen, testen en verfijnen van dit systeem kan ik een aantal concrete claims onderbouwen met werkende code en gedocumenteerde resultaten.
Automatische failover werkt. De bewaker detecteert uitval binnen negentig seconden en schakelt het DNS-verkeer om zonder menselijke interventie. Binnen twee minuten bereiken gebruikers de Europese omgeving. Terugschakeling bij herstel werkt even automatisch.
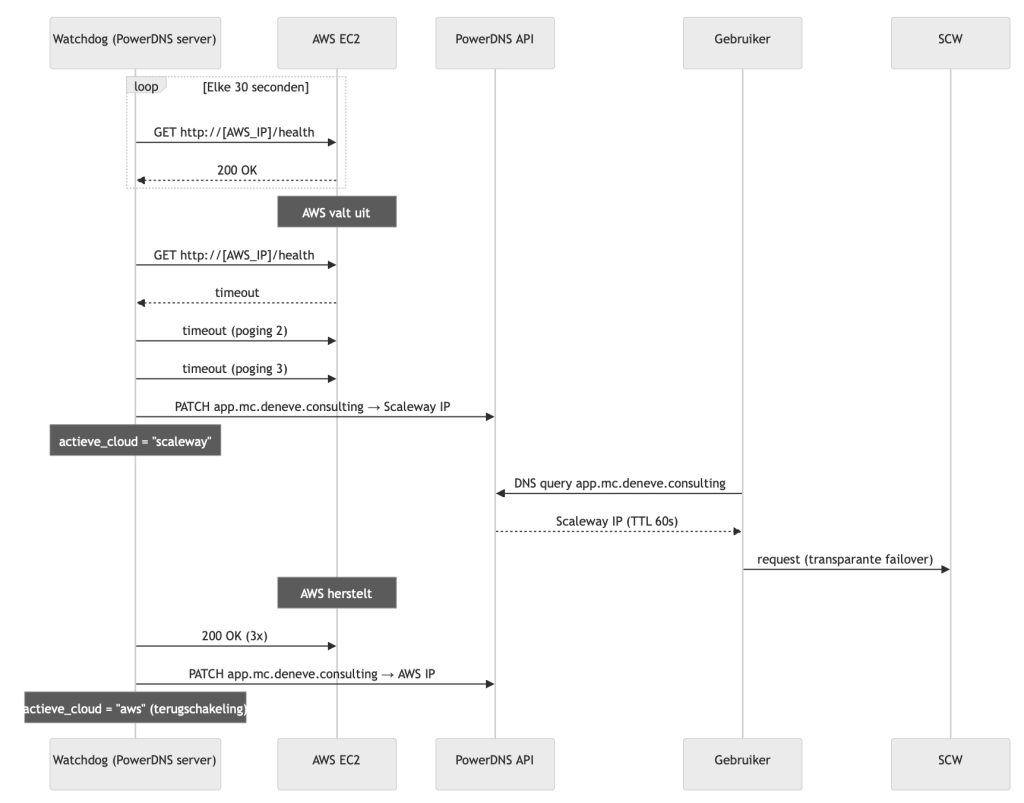
Cloud-agnostisch identiteitsbeheer werkt. Een medewerker die via het centrale Europese identiteitsplatform is geauthenticeerd, kan zowel de Amerikaanse als de Europese cloud bedienen met hetzelfde account. Als de Amerikaanse cloud geblokkeerd wordt, werkt de authenticatie door — want het identiteitsplatform draait in Europa, buiten de invloedssfeer van de geblokkeerde cloud.
Volledige automatisering via Infrastructure as Code en pipelines werkt. Zes repositories, elk met hun eigen geautomatiseerde pipeline, samen gecoördineerd zonder handmatige tussenstappen. Geen hardcoded waarden, geen configuratiedrift, geen “het werkt op mijn laptop maar niet in productie.”
De warme standby filosofie is betaalbaar én effectief. Een Europese server in warme standby heb je al vanaf zeven euro per maand. Voor dat bedrag garandeer je een hersteltijd van minder dan drie minuten en een maximaal dataverlies van minder dan vijf minuten. Dat is de verzekeringspremie voor bedrijfscontinuïteit — goedkoper dan één uur downtime van een kritiek systeem.
De EU-context: waarom dit nu relevant is
Dit project is niet gebouwd in een vacuüm. Het sluit aan bij een Europese beleidsrichting die concreter en urgenter wordt — en die ik eerder al beschreef in de context van mijn soevereine cloud.
De EU Data Act van 2024 versterkt het recht op portabiliteit en verplicht cloudaanbieders om overdracht mogelijk te maken zonder exorbitante exitkosten. Maar juridische rechten helpen niet als je de technische capaciteit niet hebt om ze te benutten. Een organisatie die haar volledige infrastructuur bij één Amerikaanse provider heeft ondergebracht, zonder documentatie, zonder automatisering, zonder enige ervaring met alternatieven, kan niet binnen acceptabele tijd migreren — ook al heeft ze het juridische recht.
NIS2 legt bestuurders persoonlijke verantwoordelijkheid op voor de continuïteit van kritieke processen. “We draaien op één grote cloudprovider en hopen dat het goed gaat” is geen aanvaardbaar continuïteitsplan meer. De richtlijn verwacht dat organisaties hun kwetsbaarheden kennen, hun herstelcapaciteit hebben getest, en kunnen aantonen dat ze in control zijn.
En dan is er het scenario waar mijn relatie terecht bezorgd over was — en waar het Internationaal Strafhof in Den Haag begin 2025 pijnlijk mee werd geconfronteerd. Een internationale instelling, juist bedoeld om boven geopolitieke belangen te staan, bleek digitaal afhankelijk van een Amerikaanse private partij die onder druk van haar eigen overheid handelde en de toegang blokkeerde. Contractuele garanties boden geen bescherming. Technische afhankelijkheid was de achilleshiel.
Mijn project is een concrete, werkende demonstratie dat het anders kan. Niet door alle eieren in een Europese mand te leggen — een grote Amerikaanse cloud als primaire omgeving kan uitstekend zijn — maar door de kritieke functies die het verschil maken bij een blokkade bewust buiten de kwetsbare zone te plaatsen. En door de technische capaciteit op te bouwen om daadwerkelijk te kunnen overschakelen wanneer dat nodig is.
De eerlijke balans
Dit project heeft ook zijn prijs, en ik zou het tekortdoen als ik die niet eerlijk benoem.
De opgebouwde documentatie telt tientallen lessons learnt — concrete problemen die ik tegenkwam en heb opgelost. Identiteitsplatforms die anders reageren dan verwacht op bepaalde verbindingsprotocollen. Automatiseringstools die bij sommige cloudomgevingen net iets anders werken dan bij andere. Timing-problemen waarbij een volgende stap start voordat de vorige volledig is afgerond.
Elk van die lessen kost tijd. Elk van die lessen levert begrip dat niet te koop is bij een managed dienst waarbij je op een knop klikt en hoopt dat het werkt. En elk van die lessen staat gedocumenteerd — zodat een relatie die mij inhuurt niet dezelfde fouten hoeft te maken, en zodat de oplossing die ik lever niet alleen werkt maar ook begrepen en beheerd kan worden.
Het grotere punt is hetzelfde als in mijn vorige artikel: digitale autonomie is een praktijk, geen eindpunt. Je bouwt het niet één keer en vergeet het. Je onderhoudt het, test het, documenteert het, en actualiseert het wanneer providers hun diensten wijzigen of wanneer de dreigingscontext verandert.
Maar de beloning is reëel. Ik kan nu een (potentiële) relatie een live demonstratie geven van een volledig automatische multi-cloud failover. Ik kan hem laten zien hoe de omschakeling plaatsvindt, hoe de authenticatie doorloopt, hoe de data gesynchroniseerd is, en hoe het systeem vanzelf terugschakelt wanneer de primaire cloud herstelt. Dat gesprek gaat daarna niet meer over de vraag of het mogelijk is — maar over hoe hij het in zijn specifieke situatie inricht.
Wat dit betekent voor uw organisatie
U hoeft dit project niet te repliceren om er waarde uit te halen. Maar er zijn drie vragen die elke organisatie zou moeten kunnen beantwoorden — en waarvan het antwoord verrassend vaak ontbreekt.
Wat zijn de functies in uw IT-landschap die absoluut niet afhankelijk mogen zijn van één provider? Toegangsbeheer en DNS zijn de twee meest onderschatte. Als uw identiteitsbeheer bij dezelfde provider draait als uw applicaties, en die provider valt weg, verliest u ook uw toegang tot de hersteltools.
Wat is uw werkelijke hersteltijd bij een volledige uitval van uw primaire cloudprovider? Niet theoretisch, maar getest. Wanneer heeft u voor het laatst een failover gesimuleerd? Weet u precies hoe lang het duurt voordat uw dienst weer operationeel is? En wie in uw organisatie weet dat?
Heeft u de technische capaciteit om uw soevereiniteitsrechten daadwerkelijk te benutten? De EU Data Act geeft u het recht op portabiliteit. Maar als u geen gedocumenteerde infrastructuur heeft, geen ervaring met alternatieven, en geen geautomatiseerde procedures, is dat recht in de praktijk illusoir.
Als onafhankelijk IT-professional help ik organisaties deze vragen concreet te beantwoorden — zonder belang bij een specifieke provider of oplossing, maar met de praktische kennis die voortkomt uit meer dan 35 jaar ervaring en het zelf bouwen en testen van deze architecturen. Want uiteindelijk gaat het niet om de technologie. Het gaat om de zekerheid dat uw organisatie blijft werken, ook wanneer een partij waarvan u afhankelijk bent een beslissing neemt die niet in uw belang is.
Dat is waar digitale soevereiniteit in de praktijk op neerkomt.
Dit artikel is het tweede deel in een reeks over het bouwen van een soevereine cloud-infrastructuur. Het eerste deel — over Kubernetes, GitOps en open source alternatieven voor Microsoft 365 — is hier te lezen. Geïnteresseerd in hoe deze aanpak vertaald kan worden naar uw organisatie? Neem contact op.
Disclaimer: Dit artikel is uitsluitend bedoeld voor informatieve en educatieve doeleinden. De beschreven architectuur weerspiegelt ervaringen opgedaan tijdens een specifiek leertraject. De genoemde cloudproviders zijn willekeurig gekozen als illustratie van het principe; de auteur is niet gelieerd aan welke provider dan ook. Prijsindicaties zijn indicatief en gebaseerd op tarieven ten tijde van publicatie. Voor toepassing in uw specifieke situatie wordt professioneel advies aanbevolen. Dit artikel is tot stand gekomen met assistentie van een AI-systeem. De technische implementatie, inhoudelijke keuzes, conclusies en eindredactie zijn volledig van de auteur.